In: Proceedings of the 31st International Joint Conference on Artificial Intelligence (IJCAI), 2022.
Samuel S. Sohn, Seonghyeon Moon, Honglu Zhou, Mihee Lee,
Sejong Yoon, Vladimir Pavlovic, and Mubbasir Kapadia
Manuscript (5.6 MB PDF) / Supplementary (10.6 MB PDF) / GitHub / NSF Project
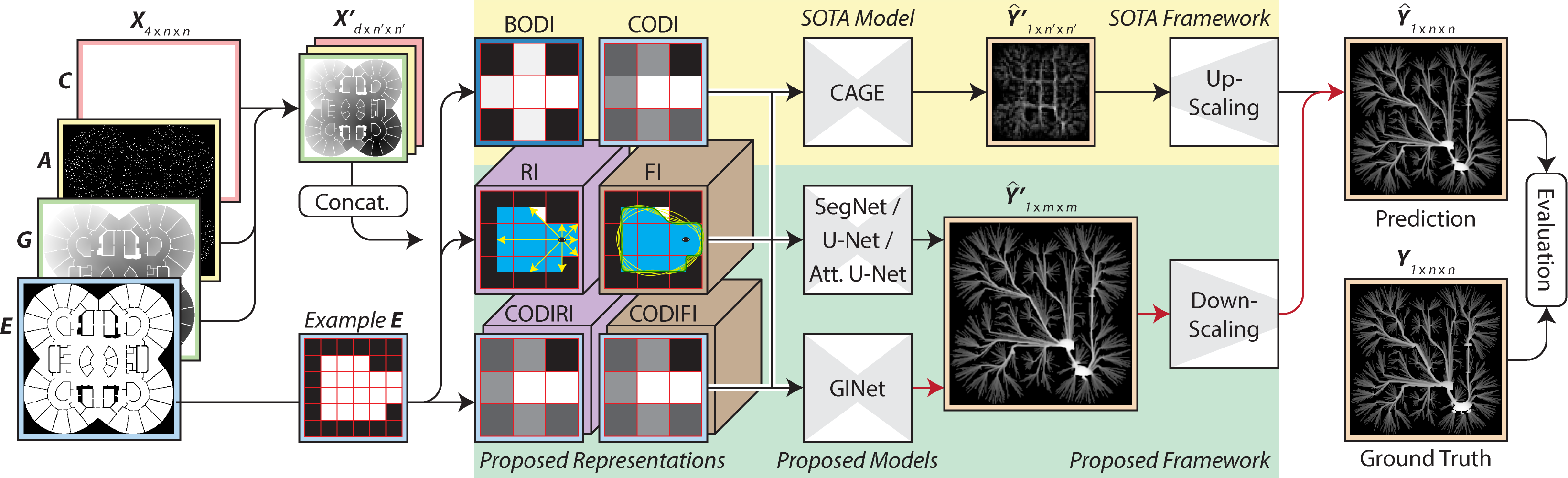
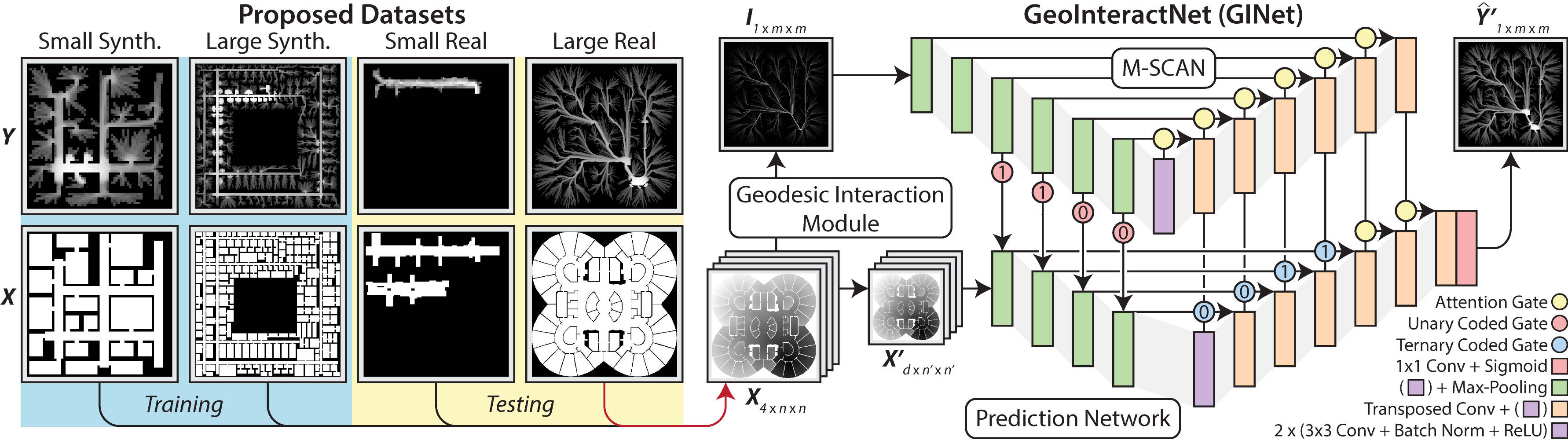
With the rise in popularity of short-term Human Trajectory Prediction (HTP), Long-Term Crowd Flow Prediction (LTCFP) has been proposed to forecast crowd movement in large and complex environments. However, the input representations, models, and datasets for LTCFP are currently limited. To this end, we propose Fourier Isovists, a novel input representation based on egocentric visibility, which consistently improves all existing models. We also propose GeoInteractNet (GINet), which couples the layers between a multi-scale attention network (M-SCAN) and a convolutional encoder-decoder network (CED). M-SCAN approximates a super-resolution map of where humans are likely to interact on the way to their goals and produces multi-scale attention maps. The CED then uses these maps in either its encoder's inputs or its decoder's attention gates, which allows GINet to produce super-resolution predictions with substantially higher accuracy than existing models even with Fourier Isovists. In order to evaluate the scalability of models to large and complex environments, which the only existing LTCFP dataset is unsuitable for, a new synthetic crowd dataset with both real and synthetic environments has been generated. In its nascent state, LTCFP has much to gain from our key contributions.